
大家好,我是作敏。
欢迎来到刚刚启航的《温故智新》小站!很高兴开启这段关于人工智能与新闻业的探索之旅。为了给这个新空间增添几分生气,我决定挑战一个颇有难度的专栏——《AI赋能数据叙事》,和大家一起聊聊如何借助AI的力量,让数据报道焕发新光彩。每期内容,我都会尽量结合一个实战案例,与你分享AI如何助力数据新闻和可视化报道的实践心得。因此,这个专栏的更新频率暂时无法给出确切的时间表——毕竟,好的内容需要耐心打磨,而灵感与案例的积累也非一朝一夕之功……
这是专栏的第一篇,姑且算作一次开篇畅谈,与你们聊聊AI,尤其是大语言模型(LLM),如何可能——或者未必能——改变我们日常报道的模样。
作为一名深耕新媒体多年的从业者,我对AI技术的潜力充满期待,同时也不禁自问:这股AI浪潮,究竟能为我们的新闻工作带来哪些实质性的改变?尤其对于地方媒体的记者来说,AI是否能成为我们手中的“探宝工具”,帮助我们从日常报道中挖掘出隐藏的“宝藏”?今天,我们就从这个问题切入,聚焦AI数据分析工具,逐步展开探讨,看看它如何为我们的报道赋能。
坦白说,开设《AI赋能数据叙事》专栏的初衷很简单:我想和你们一起,抛开关于AI的高谈阔论,真正“接地气”地摸索,它能为我们的选题和编辑室带来哪些实实在在的变化。
为此,我选择了商汤科技推出的AI数据分析工具“办公小浣熊”作为起点,带大家手把手体验大语言模型在数据分析环节,如何让我们的报道更深刻、更高效,甚至更具独特性。我们的目标不大,却很务实:希望每读完一期专栏,你都能带走一个马上可以上手的小技巧,或是一个点亮下个选题的新灵感。
当然,我也会不时提醒大家,无论技术多么迷人,新闻真实这条生命线,以及我们肩上沉甸甸的职业伦理,永远不容松懈。如果你也像我一样,好奇AI如何助力我们讲好故事;如果你渴望将冰冷的数据化为笔下掷地有声的论据和生动流淌的叙事源泉,那么,系好安全带,让我们一起启程吧!
以上,聊作《AI赋能数据叙事》的开栏语。
AI聊天机器人:万能“朋友”的软肋何在?
闲话少说,进入正题。近年来,通用型大语言模型如雨后春笋般涌现,它们对话流畅、知识广博,甚至常常让靠文字吃饭的我们自叹不如。这自然引发了一个想法:既然它们如此“全能”,能否帮我们攻克记者工作中最头疼的数据新闻?把那些看似天书的数据表格直接丢给它,让它帮忙分析,岂不是能省时省力?
这个想法听起来很诱人,但经过一番实际操作,我不得不遗憾地承认:至少在目前,让通用的聊天机器人直接处理数据分析任务,多少有些“所托非人”。它们的局限性让我一次次踩坑,接下来,我会拆解几点,与大家分享我的心得体会。
首先,是结构认知上的“只见树木,不见森林”。通用大模型在处理自然语言方面表现出色,但面对结构化数据——比如我们日常使用的Excel表格——往往显得力不从心。它们能够识别文字和数字,却难以理解表格的内在逻辑,比如列与列之间的关联、合并单元格的含义,甚至复杂数据库的设计模式。对它们而言,数据更像是一幅“图画”,通过模式匹配来猜测,而非真正进行解析和计算。
我曾让Gemini 2.5 Pro分析一个结构化表格,要求模型分析两组数据的相关性。它给出的论述看似专业,但选用的方法并不适用,解读也过于绝对,忽略了可能的混杂因素。这就像请一位辩论家解高等数学题,讲得天花乱坠,答案却未必站得住脚。
其次,是统计推断上的“能说会道,不精计算”。数据分析,尤其是调查性报道,离不开严谨的统计方法。通用模型看似能生成一段头头是道的统计描述,甚至写出几行代码,但它们并非统计学家。它们无法判断哪种模型适合当前数据,也不会科学地检验假设或解释系数的意义。
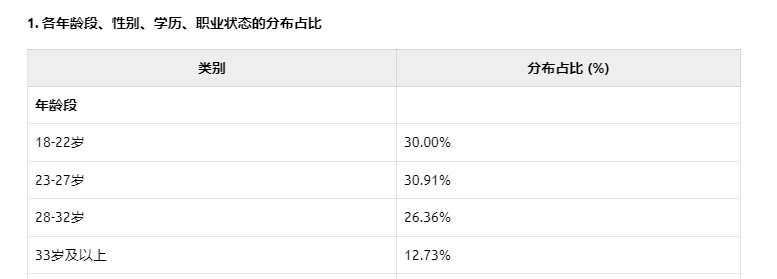
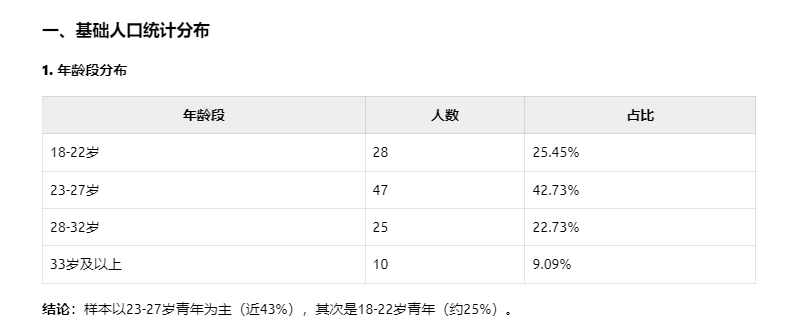
上周,我在温青夜校进行了一次AI辅助数据分析的实践。在课堂的实战案例中,我设计了一次演示,邀请当今最顶尖的四个大模型——Gemini 2.5 Pro、Grok3、Claude 3.7 和 DeepSeek R1——分析一份关于“社区青年数字素养调研”的模拟数据表格。然而,这三个模型在最基础的第一关就纷纷“翻车”。我的问题非常简单:请告诉我表格中各年龄段、性别、学历和职业状态的分布占比。结果令人失望,没有一个模型给出了正确答案。那一刻,我深刻感受到,这些模型仅仅停留在“看图识字”的层面,表面上识别了数据,却完全没有进行实际计算,更无法洞察数据的“森林”,只是在靠猜测输出答案。


最后,是那臭名昭著的“幻觉”风险。模型为了让回答流畅自信,有时会编造事实或数据。在日常闲聊中,这种“幻觉”或许还能博人一笑,但在新闻领域,若误将“幻觉”当事实,后果不堪设想。但凡用过DeepSeek的朋友都知道,它张口就能编造各种精确到小数点后好几位的数字,以至于我现在看到一篇满是数据的文章,都会怀疑是否是DeepSeek的杰作。这为我们媒体人的真实性底线敲响了警钟。
所以,我的看法是,通用聊天机器人更像是知识渊博的“清谈客”,偶尔能启发思路,但要让它们成为严谨的“账房先生”,还远远不够格。面对数据分析,我们急需更专业、更靠谱的工具。
专业数据分析工具:利器在手,为何难上手?
既然通用模型“不靠谱”,我们自然想到另一条路:那些久经考验的专业数据分析工具,比如Excel的高级功能、统计领域的SPSS、学术界常用的R语言和Python,以及炫酷的Tableau、Power BI等商业智能平台。它们是数据分析的“正规军”,功能完善、计算精准,远非聊天机器人可比。
然而,对我们这些以文字为“兵器”、每天与截稿日期赛跑的媒体人来说,掌握这些工具绝非易事,甚至是一条崎岖的“习武”之路。我来聊聊几点困难,或许你也有同感。
首先,是令人望而却步的学习曲线。以R或Python为例,尽管网上有海量教程和社区支持,但从安装环境到理解“天书”般的语法,再到独立完成数据清洗和可视化,所需的时间和精力对我们来说往往是巨大门槛。我自己就曾经满怀雄心买回编程教材,结果翻几页就因“没时间”或“看不懂”而放弃,书只能在架子上积灰。
其次,是思维模式上的“频道切换”。这些工具背后是一套与人文叙事不同的逻辑,比如数据库的规范化、统计的假设检验、编程的算法思维。这对习惯感性认知和质性分析的媒体人来说,确实是个不小的挑战,有时甚至让人“怀疑人生”。
最后,是场景适配上的“性价比”问题。如果是大规模、复杂的调查性报道,R和Python这些“重型武器”不可或缺。但日常工作中,我们的需求往往是处理简单的Excel表格,算算占比或做个柱状图。每次启动复杂工具,甚至写代码,未免有“杀鸡用牛刀”之感,效率未必高。
通用模型有“不可承受之轻”,专业工具又有“难以企及之高”,那么,有没有一种折中的AI解决方案,既易用又具一定专业性,更贴合我们媒体人的日常需求呢?
“办公小浣熊”:数据分析的“量身定制”之道
答案是肯定的。
就在我为这个“两难”挠头时,一些针对特定领域优化的大语言模型进入了视野。其中,商汤科技基于“日日新”(SenseNova)模型推出的“办公小浣熊”,似乎在通用模型的便捷性与专业数据分析需求间架起了一座桥梁。初步体验后,我觉得它可能为我们这些有“技术恐惧症”的媒体人提供新思路,下面和你们分享几点亮点。
第一,专为结构化数据“排兵布阵”。不同于“万金油”式的通用模型,“办公小浣熊”天生带着“办公基因”,针对数据分析深度优化。它能处理Excel、CSV、JSON等多种格式,号称能“看懂”合并单元格、多级表头等复杂表格,甚至支持多文件整合分析。这意味着,我们的原始表格可能直接丢给它,无需繁琐预处理。光这一点,如果真能做到,就能省下多少重复劳动!
第二,“张张嘴”就能驱动分析。它的最大魅力在于自然语言交互,极大地降低了技术门槛,让非技术背景的用户也能轻松上手。无需记忆繁琐的函数或学习编程语言,只需像聊天一样用大白话提出你的数据分析需求。譬如上面那个“社区青年数字素养调研”的模拟数据表格,我提问:“不同年龄段的青年在’最想学的数字技能 (Skill_Interest_1)‘上是否存在明显偏好差异?请分别列出每个年龄段选择最多的 Top 2 技能。”

办公小浣熊精准地理解了这个涉及到分组、筛选和排序的复杂指令,并迅速生成了各年龄段青年最青睐的Top 2数字技能及其选择人数的“结论”表格。 这种“所说即所得”的高效体验,真正让我们这些“文字兵器”也能轻松“玩转”数据。
第三,图表报告“一键生成”的潜力。新闻报道中,将数据分析结果转化为直观图表或简洁报告至关重要,尤其是在赶时效时。“办公小浣熊”内置的可视化功能,能根据用户的自然语言指令自动生成图表。譬如,我提出“为下面的需求提供可视化图表:青年对数字技能(尤其是AI、编程、数据分析)的整体兴趣水平,对特定技能(如AI)的了解程度分布”这样的请求后,小浣熊迅速响应,生成了名为“青年对AI、编程、数据分析等数字技能的兴趣水平”的柱状图,清晰地展示了不同技能的兴趣占比。
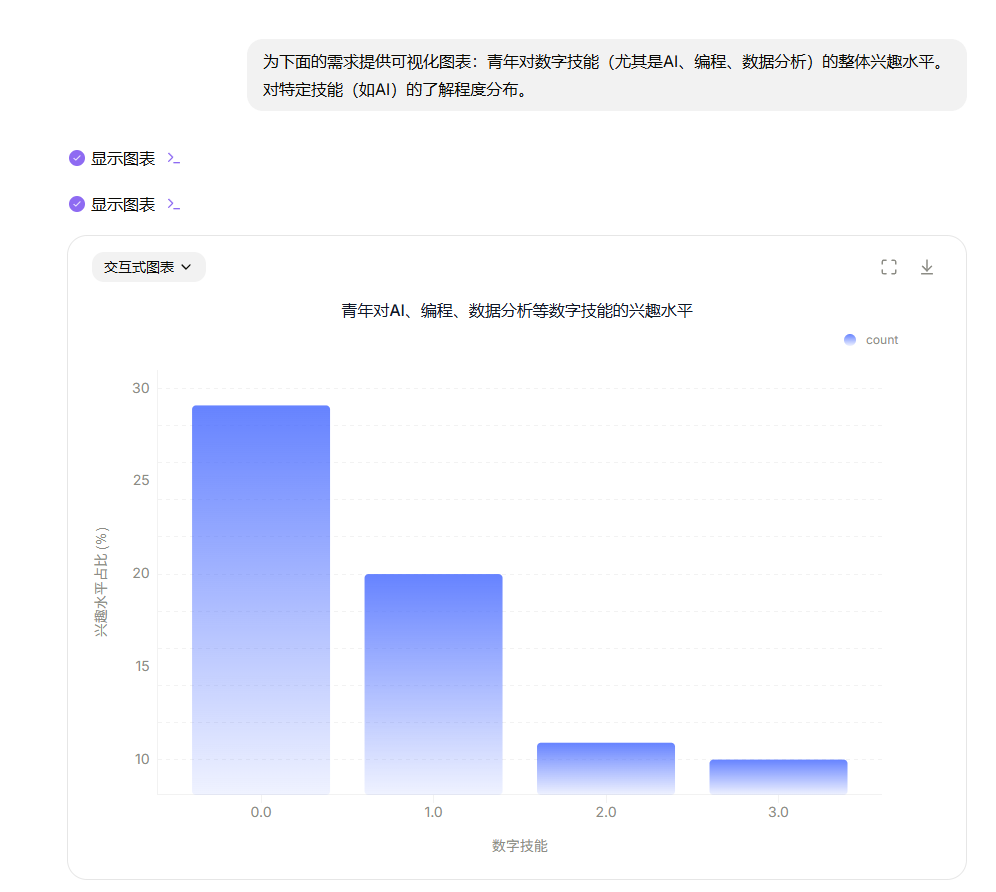
这种无需复杂操作、直接通过自然语言生成图表的体验,极大地提升了我们将数据结论视觉化的效率,让复杂的数字变得一目了然。如果这一功能稳定且支持多种图表类型,将能显著增强我们报道的可读性和感染力,为新闻内容增色不少。
记者能用它做什么?几个场景畅想
光说不练假把式。基于“办公小浣熊”的功能,我大胆设想了几个本地报道的场景,和你们一起脑洞一下,看看它能在实际工作中发挥怎样的作用。
场景一:快速“解剖”政府预算报告。每年两会期间,政府公开的预算表格层层叠叠,数据繁杂,看得人眼花缭乱。如果我们将某部门的预算表上传,直接问:“找出‘三公’经费的各项数额、总额,并与去年对比增减百分比,生成对比柱状图。”若它能快速准确地完成分析和可视化,就能省去大量人工核对和计算的时间,让我们将精力聚焦在解读和报道上!
场景二:从民生数据“揪出”异常波动。温州开放数据平台提供了不少民生数据,比如12345热线投诉量。如果我们上传数据后问:“分析这份投诉数据,哪个区县在某个月份投诉量突增?主要集中在哪些领域?”这种异常往往隐藏着民生热点或管理问题,抓住这些“异动”,或许就能挖出值得关注的新闻点。
场景三:用多源数据“碰撞”独家线索。有时,深度选题需要多维度数据的“化学反应”。假设我们有温州近五年的常住人口、商品房销售和入学人数数据,可以问:“结合这三份数据,哪些区域的人口增长与住房、教育资源之间存在显著关联或明显不匹配?”这样的分析或许能引出关于城市规划或资源配置的调查报道,为深度选题提供数据支撑。
当然,新工具也伴随着未知数。它的实际表现究竟如何?面对复杂或低质量的数据能否胜任?数据安全和隐私保护措施是否到位?这些问题,都是我们专栏将在后续实践中以批判的眼光去检验的。毕竟,工具只是辅助,记者的洞察力和责任感才是报道的根本。
结语:选对“洛阳铲”,挖出深层“宝藏”
聊了这么多,我想说的是:AI时代确实为我们媒体人的数据分析打开了想象空间。通用聊天机器人知识渊博却不擅专业分析,传统工具功能强大却难上手。而以“办公小浣熊”为代表的领域优化AI工具,或许能为我们提供一条便捷高效的路径,用自然语言驾驭原本需专业技能才能触及的数据。
工具从来不是目的。真正能帮我们发现真相、挖掘故事、传播价值的,才是我们要找的那把“洛阳铲”。我希望与你们一起,以开放心态尝试新技术,同时保持审慎目光审视其利弊。在AI赋能数据叙事的路上,我们共同求索,择善而从。
下一期,我将更具体地分享如何使用这类工具操作数据,以及享受技术红利时需警惕的“坑”与“雷”。期待与你们再会!